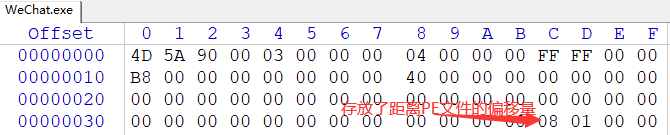
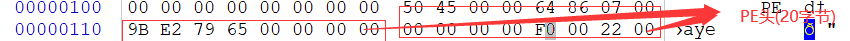PE文件 PE文件结构 MS-DOS存根 MS-DOS存根是放置在EXE映像之前,MS-DOS存根标识MS-DOS下运行的有效程序。链接器会默认在存根的位置放置一个默认存根标识程序无法在DOS系统下运行[用户可以在STUB链接器选项来指定不同的存根]。在0x3C的位置,存根存放了距离PE签名的的偏移量。stub的范围由MZ头的结构体中成员e_lfanew来决定。
PE签名 根据MS-DOS存根在0x3C位置存放的偏移量(本次的示例exe文件是08 01 00 00),可以找到PE签名的部分(4字节),PE签名(50 45 00 00)(由于文件的存储为小端序所以直接读取的字节需要调整顺序为大端序进行阅读)查看偏移量为0x108的位置,就可以查看PE文件的签名。
https://shell-storm.org/online/Online-Assembler-and-Disassembler)。
DOS头(MZ头) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 typedef struct _IMAGE_DOS_HEADER { WORD e_magic;//文件的魔数(PE文件的魔数固定为4D 5A) WORD e_cblp; WORD e_cp; WORD e_crlc; WORD e_cparhdr; WORD e_minalloc; WORD e_maxalloc; WORD e_ss; WORD e_sp; WORD e_csum; WORD e_ip; WORD e_cs; WORD e_lfarlc; WORD e_ovno; WORD e_res[4]; WORD e_oemid; WORD e_oeminfo; WORD e_res2[10]; LONG e_lfanew;//标识PE文件的头部偏移量也是DOS头的结束位置(可以通过查询这个偏移量查询文件的PE签名位置,该成员的数据取决于文件的不同) } IMAGE_DOS_HEADER,*PIMAGE_DOS_HEADER;[(PIMAGE_DOS_HEADER)表示指向这个MZ头结构体的指针]
DOS的功能主要是用于适配DOS操作系统,在windows操作系统使用中只有MZ头的e_magic(WORD)和e_ifanew(LONG)两个字段在windows操作系统中有效。DOS头中的成员除了e_magic和e_ifanew两个字段,都是可以更改为其他的值,DOS可以人为进行写入一些数据,即使全部改为0,对文件在Windows系统下的运行没有任何影响。
NT头(PE头) 1 2 3 4 5 6 7 8 9 10 11 typedef struct _IMAGE_NT_HEADERS64 { DWORD Signature;//PE签名 文件头标志 IMAGE_FILE_HEADER FileHeader;//文件基本信息文件头 IMAGE_OPTIONAL_HEADER64 OptionalHeader;//文件拓展信息可选头 } IMAGE_NT_HEADERS64,*PIMAGE_NT_HEADERS64;//64位 typedef struct _IMAGE_NT_HEADERS { DWORD Signature;//PE签名 文件头标志 IMAGE_FILE_HEADER FileHeader;//文件基本信息文件头 IMAGE_OPTIONAL_HEADER32 OptionalHeader;//文件拓展信息可选头 } IMAGE_NT_HEADERS32,*PIMAGE_NT_HEADERS32;//32位
PE头由PE文件标志(50 45 00 00),标准PE头和拓展PE头组成。PE头用于真正装在win32和win64文件,32和64的区别在于PE拓展头的大小不同,32位下PE拓展头为224字节,64位下PE拓展头为240字节(0x10b 为32位文件 0x20b为64为文件 )。
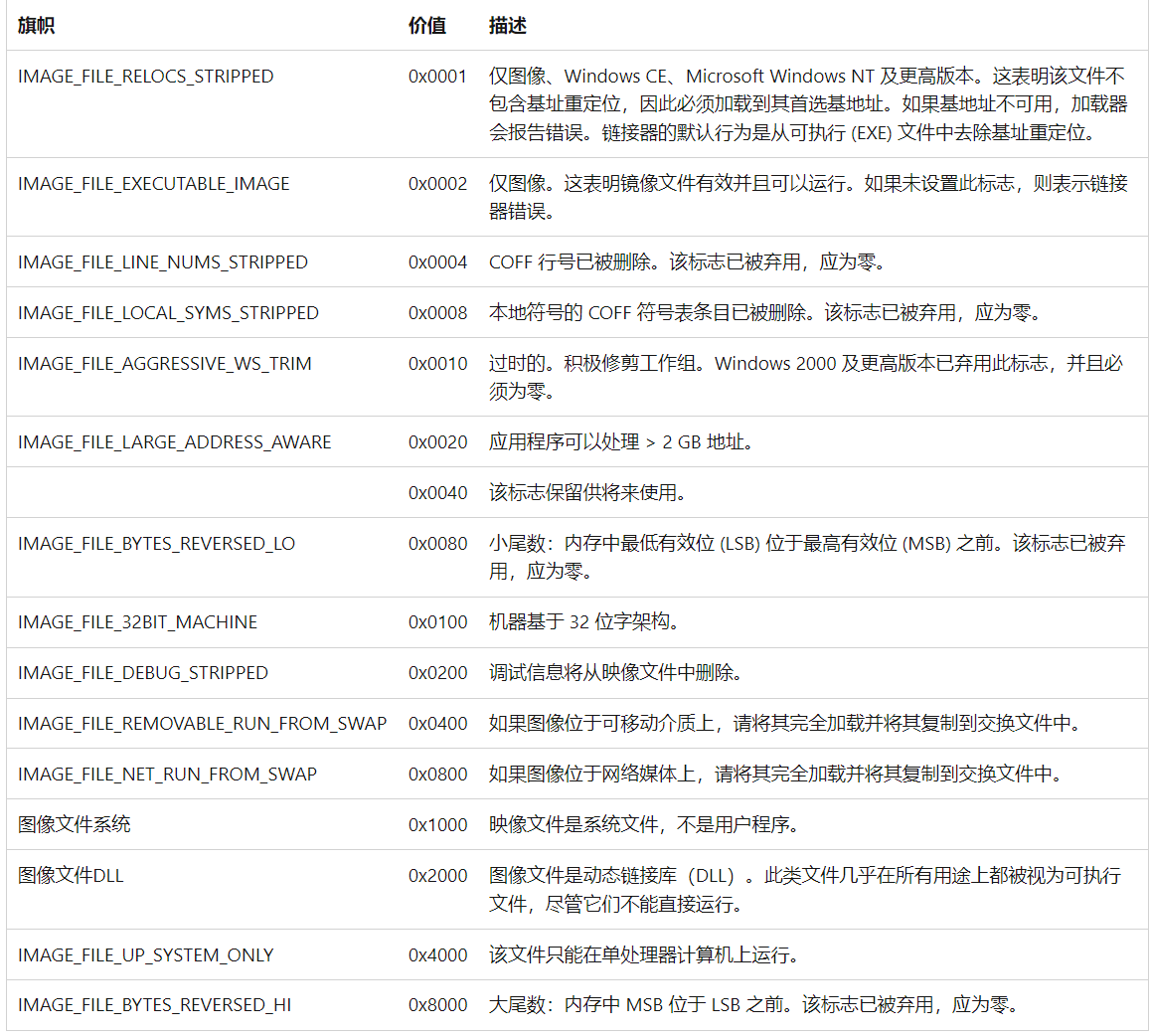
1 2 3 4 5 6 7 8 9 typedef struct _IMAGE_FILE_HEADER { WORD Machine;//指定运行的CPU类型,映像文件只能在指定的计算机或虚拟机上运行 可以粗略的判断是32位还是64位程序 但是IMAGE_OPTIONAL_HEADER 的e_magic成员判断的更为准确 WORD NumberOfSections;//表示节的数量 (可以用于计算节表的大小) DWORD TimeDateStamp;//编译器填写的时间戳(与文件属性中的创建时间和修改时间无关 链接器创建image的时间) DWORD PointerToSymbolTable;//符号表的偏移量,不存在符号表则为0 DWORD NumberOfSymbols;//符号表中的符号数 WORD SizeOfOptionalHeader;//拓展PE头(可选头的大小) WORD Characteristics;//特征 } IMAGE_FILE_HEADER,*PIMAGE_FILE_HEADER;
characteristics
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 typedef struct _IMAGE_OPTIONAL_HEADER { WORD Magic;//镜像文件的状态,可用于判断是32位还是64位 BYTE MajorLinkerVersion;//链接器的主版本号 BYTE MinorLinkerVersion;//链接器的次版本号 DWORD SizeOfCode;//代码段的大小(文件对齐后的大小) DWORD SizeOfInitializedData;//初始化数据段的大小 DWORD SizeOfUninitializedData;//未初始化数据段的大小 在有多个未初始化的数据段时,则为这些数据段的大小总和 文件对齐后的大小 DWORD AddressOfEntryPoint;//入口点 指向入口点函数的指针 对于可执行文件来说,成员的值为程序的起始地址 对于驱动程序,成员的值为驱动初始化函数的地址 入口点函数对于dll时可选的,当没有入口点时,成员为0 DWORD BaseOfCode;//代码开始的基址 DWORD BaseOfData;//数据开始的基址 DWORD ImageBase;//内存镜像基址 IMAGE文件载入内存时的第一个字节的首选地址,该值是64字节的倍数 dll的默认值是0x10000000 应用程序的默认值是0x40000000 windows CE 的默认值是0x00010000 DWORD SectionAlignment;//内存对齐(必须大于等于FileAlignment成员) 默认值是系统的界面大小 DWORD FileAlignment;//文件对齐 默认值是512 如果SectionAilgnment成员小于系统界面大小,成员必须与SectionAlignment成员一致 WORD MajorOperatingSystemVersion;//操作系统主版本号 WORD MinorOperatingSystemVersion;//操作系统次版本号 WORD MajorImageVersion;//PE文件自身的版本号 映像的版本号 WORD MinorImageVersion;//PE文件自身的版本号 映像的版本号 WORD MajorSubsystemVersion;//运行时所需子系统主版本号 WORD MinorSubsystemVersion;//运行时所需子系统次版本号 DWORD Win32VersionValue;//子系统的版本值必须为0 DWORD SizeOfImage;//映像的大小 DWORD SizeOfHeaders;//所有头+节表的大小(可以用于计算节表的大小) DWORD CheckSum;//校验和 Image(PE文件)校验和,文件在加载时进行验证,所有驱动程序,引导时加载的任何DLL,以及加载到任何关键系统进程中的任何DLL WORD Subsystem;//子系统 WORD DllCharacteristics;//文件的特征 特征表中从上到下分别为16进制数的最低位到最高位 DWORD SizeOfStackReserve;//初始化时保留的栈大小 DWORD SizeOfStackCommit;//初始化实际提交的栈大小 DWORD SizeOfHeapReserve;//初始化保留的堆大小 DWORD SizeOfHeapCommit;//初始化实际提交的堆大小 DWORD LoaderFlags;//调试相关 DWORD NumberOfRvaAndSizes;//目录项数目 IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES](16个字段一共是128字节);指向IMAGE_DATA_DIRECTORY结构体指针 } IMAGE_OPTIONAL_HEADER32,*PIMAGE_OPTIONAL_HEADER32;//拓展头的32位版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 typedef struct _IMAGE_OPTIONAL_HEADER64 { WORD Magic; BYTE MajorLinkerVersion; BYTE MinorLinkerVersion; DWORD SizeOfCode; DWORD SizeOfInitializedData; DWORD SizeOfUninitializedData; DWORD AddressOfEntryPoint; DWORD BaseOfCode; ULONGLONG ImageBase; DWORD SectionAlignment; DWORD FileAlignment; WORD MajorOperatingSystemVersion; WORD MinorOperatingSystemVersion; WORD MajorImageVersion; WORD MinorImageVersion; WORD MajorSubsystemVersion; WORD MinorSubsystemVersion; DWORD Win32VersionValue; DWORD SizeOfImage; DWORD SizeOfHeaders; DWORD CheckSum; WORD Subsystem; WORD DllCharacteristics; ULONGLONG SizeOfStackReserve; ULONGLONG SizeOfStackCommit; ULONGLONG SizeOfHeapReserve; ULONGLONG SizeOfHeapCommit; DWORD LoaderFlags; DWORD NumberOfRvaAndSizes; IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES]; } IMAGE_OPTIONAL_HEADER64,*PIMAGE_OPTIONAL_HEADER64;//拓展头的64位版本
1 2 3 4 typedef struct _IMAGE_DATA_DIRECTORY { DWORD VirtualAddress;//文件的虚拟地址 DWORD Size;//文件的大小 } IMAGE_DATA_DIRECTORY,*PIMAGE_DATA_DIRECTORY;
堆栈保留大小 堆栈提交大小 堆栈保留大小(stack reservrd size)操作系统为一个进程或一个线程分配的堆栈空间的大小。在创建线程或进程时,操作系统会为其分配一块内存空间用于堆栈。这个内存空间的大小就是堆栈保留大小。堆栈保留空间可以设置为一个固定的值,也可以进行动态调整。
下列项的组合大小,舍入”文件对齐”成员中指定的倍数
SizeofHeaders(所有节表的大小)={e_lfanew+sizeof(Signature)+sizeof(IMAGE_FILE_HEADER)+sizeof(IMAGE_OPTIONAL_HEADER)+sizeof(IMAGE_SECTION_HEADER)}
三种PE地址 PE结构存在三种地址VA(虚拟地址) RVA(相对虚拟地址) FILEOFFEST(文件偏移地址)
地址转换 VA转RVA通过将VA的值减去文件拓展头中ImageBase(映像的虚拟地址)得到RVA。
1 2 3 4 5 6 7 CheckSumMappedFile函数(imagehlp.h)计算指定映射文件的较严格 PIMAGE_NT_HEADERS IMAGEAPI CheckSumMappedFile( [in] PVOID BaseAddress,//映射文件的基地址 调用MapViewOfFile函数进行获取 [in] DWORD FileLength,//文件的大小 [out] PDWORD HeaderSum,//指向文件接收原始校验和变量的指针 [out] PDWORD CheckSum//指向接收计算的校验和的变量的指针 );
CheckSumMappedFile函数计算文件的新校验和并且返回到CheckSum的参数中。所用的ImageHlp函数(例如这个函数)都是单线程的。因此,从多个线程调用此函数可能会导致意外行为或者内存损坏。
1 2 3 4 5 6 MapFileAndCheckSumA函数(imagehlp.h)函数用于检测checksum DWORD MapFileAndCheckSum( [in] PCSTR FileName,//要计算校验和的文件名 [out] PDWORD HeaderSum,//指针指向PE文件头中的校验和 [out] PDWORD CheckSum//指针指向新计算的校验和 );
程序一旦运行起来,将会存放当前文件的CheckSum。
节头 节头在文件中没有被直接指向,此表紧跟在可选头之后,需要自行定位.节表的位置通过计算头后第一个字节的位置进行确定.在节表中每一个节都是一个节头。节表中条目数由文件头中NumberofSections字段进行确定(节表的条目由1开始确定)。
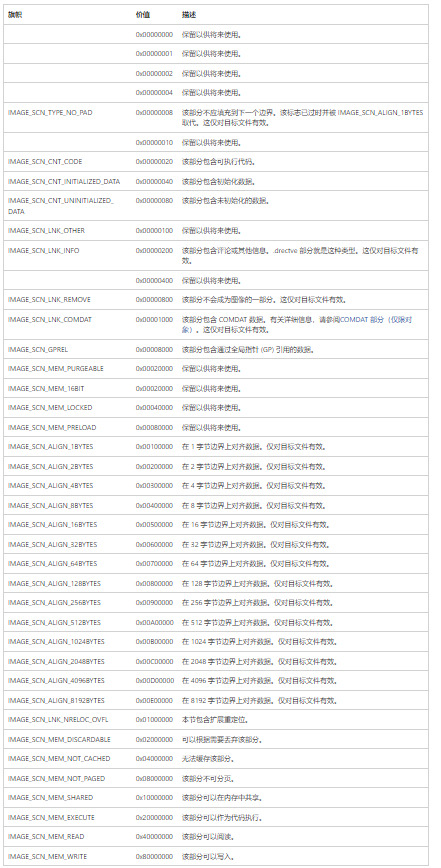
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 相同的节表会按照节的名称的先后顺序进行分配。 typedef struct _IMAGE_SECTION_HEADER { BYTE Name[IMAGE_SIZEOF_SHORT_NAME];//名称 Name BYTE[8]=8字节 使用ascii码进行存储 union { DWORD PhysicalAddress;//物理地址 文件地址 DWORD VirtualSize;//节的虚拟大小 节加载到内存中的总大小,若这个值大于SizeOfRawData成员则这个节会被0进行填充 节的虚拟大小如果超出节的 } Misc;//Misc双字,字段是union型数据,这是该节在没有对齐前的真实尺寸 DWORD VirtualAddress;//虚拟地址 section载入内存的第一个字节的地址,相对于ImageBase。对于object files来说,是应用重定位之前的第一个字节的地址 虚拟地址加上ImageBase计算虚拟地址 DWORD SizeOfRawData;//节在文件对齐之后的大小(磁盘上初始化的数据大小这个大小必须是IMAGE_OPTIONAL_HEADER成员FILEALIGNMENT的倍数) DWORD PointerToRawData;//指向COFF文件中的第一页文件指针 节区在文件中的偏移 FILEOFFESTADDRESS 文件偏移地址 DWORD PointerToRelocations;//执行节的重定向的位置的文件指针 在obj文件中使用的指向重定位表的指针 DWORD PointerToLinenumbers;//执行coff行号的条目起始的文件指针(coff行号已经弃用) 指向行号表的指针供调试使用 WORD NumberOfRelocations;//重定位表的个数(在obj文件中使用) WORD NumberOfLinenumbers;//section的行号表行号条目 DWORD Characteristics;//节标志 } IMAGE_SECTION_HEADER,*PIMAGE_SECTION_HEADER;
节表存在一个联合体Misc,联合体两个字段表示节的物理地址(Misc.PhysicalAddress)和节的虚拟大小(Misc.VirtualSize)。
obj文件:VS工程文件中的.obj文件 obj文件包含机械码或字节码以及其他数据和元数据的文件 由编译器或者是在汇编过程中生成被称为目标代码 目标代码可以进行重定位,同城不能直接执行类似于DLL文件可以像共享库文件一样进行工作 目标文件包含的元数据可以用于连接或者调试 包括解决不同模块之间符号交叉引用 重定位 堆栈展开信息 注释 程序符号 调试或分析信息
导入表 导入表定位 PE拓展头的DataDirectory[1]定位导入表的地址 DataDirectory[1].VirtualAddress
1 2 3 4 5 6 7 8 9 10 11 typedef struct _IMAGE_IMPORT_DESCRIPTOR { union { DWORD Characteristics; //标志0标识没有导入标识符 DWORD OriginalFirstThunk; //RVA指向IMAGE_THUNK_DATA结构数组 桥1 INT(Import Name Table)导入名称表 } DUMMYUNIONNAME; DWORD TimeDateStamp;//时间戳 DWORD ForwarderChain;//链表的前一个结构 DWORD Name;//RVA指向dll的名字以"\0"结尾 DWORD FirstThunk;//RVA指向IMAGE_THUNK_DATA结构数组 桥2 IAT(Import Address Table)导入地址表 } IMAGE_IMPORT_DESCRIPTOR; typedef IMAGE_IMPORT_DESCRIPTOR UNALIGNED *PIMAGE_IMPORT_DESCRIPTOR;
导入表存在双桥结构 第一个OrignalFirstThunk指向桥1,FirstThunk指向桥2。双桥结构在PE文件运行之前INT和IAT中两个数据相同但储存位置不同(IMAGE_THUNK_DATA)。在PE文件运行之后,桥1指向INT(INT中存放了导入函数的函数标号),桥2指向IAT(IAT中存放了导入函数的地址)。桥2与指向IMAGE_IMPORT_BY_NAME的结构断开。
导出表 1 2 3 4 5 6 7 8 9 10 11 12 13 typedef struct _IMAGE_EXPORT_DIRECTORY { DWORD Characteristics;//未使用 DWORD TimeDateStamp;//时间戳 与PE标准头中时间戳含义相同 WORD MajorVersion;//未使用 WORD MinorVersion;//MinnorVersion DWORD Name;//指向一个以"\0"结尾的字符串 记录了导出表所在文件的文件名 DWORD Base;//导出函数序号的起始值 导出函数的序号是由AddressOfFunctions+函数的顺序号进行计算的,fun1的函数标号为nbase(200h)+0(索引值),fun2的函数标号为nbase+1(索引值) DWORD NumberOfFunctions;//导出函数的个数 DWORD NumberOfNames;//导出函数的函数名 NumberOfNames<=NumberOfFunctions一部分函数回重复使用一些函数名 DWORD AddressOfFunctions;//指向全部导出函数的入口点的起始,从入口点开始为DWORD数组,数组的个数由NumberOfFunctions决定 导出函数的二米一个地址函数函数的编号顺序一次往后排开,在内存中可以通过函数的编号对函数的地址进行定位 DWORD AddressOfNames;//指向位置为一连串的DWORD值 值指向了定义了函数名的函数的字符串地址,DWORD的个数由NumberOfNames决定 DWORD AddressOfNameOrdinals;//指针与AddressOfNames是一一对应的关系 与AddressOfNames不同的是AddressOfNameOrdinals指向的是函数了AddressOfFunctions中的索引值 } IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
导出表的就是记录PE文件提供给其他的PE文件函数的一种结构 在文件拓展头中存在一个数据结构IMAGE_DATA_DIRECTORY
1 2 3 4 5 typedef struct _IMAGE_DATA_DIRECTORY { DWORD VirtualAddress;//表的RVA DWORD Size;//表的大小 } IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
导出表导出函数两种方式:名称导出 序号导出
重定位表 重定位技术:
1 2 3 4 5 6 7 8 9 10 _asm{ _code: xor eax,eax mov eax,ds:[_data] jmp _end _data: _emit 0x61 _end:mov result,eax }
类似这样的代码如果jmp一个绝对地址那么在内存存储的内容发生变化的情况下,代码就不会正常运行出正确的结果。所以我们需要通过一些手段将代码使用的绝对地址替换为相对地址。例如添加一个标签
重定位表的定位 类似于导入导出表的定位方式查找文件拓展头的IMAGE_DATA_DIRECTORY结构的DataDirectory[5]对重定位表进行定位,通过DataDirectory[5].VirtualAddress对导入表的RVA进行定位,将导出表的RVA转换为FOA,在文件中定位到重定位表。
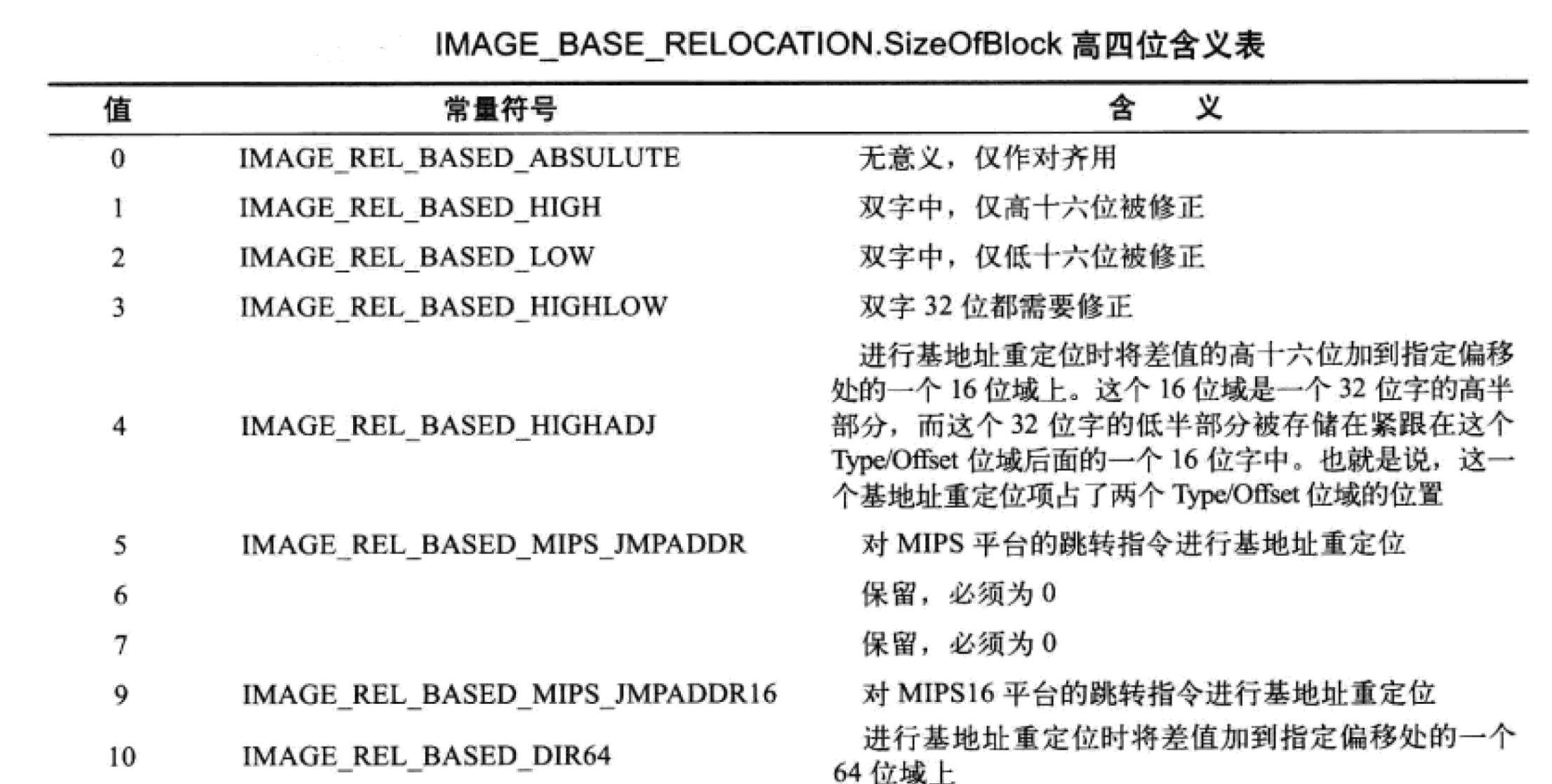
1 2 3 4 5 6 typedef struct _IMAGE_BASE_RELOCATION { DWORD VirtualAddress;//重定位内存页的起始RVA DWORD SizeOfBlock;//重定位块的长度 // WORD TypeOffset[1]; 原则上不属于这个结构 } IMAGE_BASE_RELOCATION; typedef IMAGE_BASE_RELOCATION UNALIGNED * PIMAGE_BASE_RELOCATION;
重定位表指针指向了一个数组,类似于导入表结构,都存在其他的结构对数据的进行了存储。为了节省存储空间,将重定位表划分为了多个重定位块。如果存储重定位的地址,那么会有大量的地址数据需要载入内存进行存储,如果直接存储地址会消耗大量的内存,而重定位块,设置了基地址,将相同基地址的数据存放在一起,采用基地址+偏移的方式进行存储,也就是说数据的相同部分不需要多次存储而是建立一个数据目录,只存储偏移,从而节省内存。
重定位块SizeOfBlock后的数据部分作为偏移进行使用,每一个数据项的大小为WORD,但是只有后12位表示偏移。一个重定位块对应一个物理内存页(4kb=2^12),所以只需要12位对内存页进行表示。
资源表 资源表用于来储存程序的各种界面数据,比如说菜单,图标,版本信息,版本信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 typedef struct _IMAGE_RESOURCE_DIRECTORY { DWORD Characteristics; DWORD TimeDateStamp; WORD MajorVersion;//资源主版本,通常为0x0004 WORD MinorVersion;//资源子版本,通常为0x0000 WORD NumberOfNamedEntries;//资源名称条目的个数 WORD NumberOfIdEntries;//资源条目ID的个数 // IMAGE_RESOURCE_DIRECTORY_ENTRY DirectoryEntries[]; } IMAGE_RESOURCE_DIRECTORY, *PIMAGE_RESOURCE_DIRECTORY; typedef struct _IMAGE_RESOURCE_DIRECTORY_ENTRY { union { struct { DWORD NameOffset:31;//资源名偏移 DWORD NameIsString:1;//资源名为字符串 } DUMMYSTRUCTNAME; DWORD Name;//资源/语言类型 WORD Id;//资源数字ID } DUMMYUNIONNAME; union { DWORD OffsetToData;//数据偏移地址 struct { DWORD OffsetToDirectory:31;//子目录偏移地址 DWORD DataIsDirectory:1;//数据为目录 } DUMMYSTRUCTNAME2; } DUMMYUNIONNAME2; } IMAGE_RESOURCE_DIRECTORY_ENTRY, *PIMAGE_RESOURCE_DIRECTORY_ENTRY;
第一个联合体的信息,是根据当前结构体所处的目录层次来决定的。位于第一层目录时Name有效,保存的信息是资源类型。位于第二层目录时ID或结构体有效,取决于资源的索引方式,如果是编号索引就是ID有效,否则是结构体有效。位于第三层目录时Name有效,保存的信息是语言类型。
PE文件解析器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 #include <stdio.h> #include <iostream> #include <stdlib.h> #include <windows.h> #include <winnt.h> #include <fileapi.h> #include<math.h> #include <algorithm> UINT VatoFoa32(UINT va, PIMAGE_DOS_HEADER dos, PIMAGE_NT_HEADERS32 nt, PIMAGE_SECTION_HEADER* sectionArr) { UINT rva = va - nt->OptionalHeader.ImageBase; //std::cout << "rva:" << rva << std::endl; UINT peend = (UINT)dos->e_lfanew + sizeof(IMAGE_NT_HEADERS32); if (rva < peend) { //std::cout << "foa" << rva << std::endl; return rva; } else { //判断地址处于那个节 int i; for (i = 0; i < nt->FileHeader.NumberOfSections; i++) { UINT SizeInMemory = ceil((double)max((UINT)sectionArr[i]->Misc.VirtualSize, (UINT)sectionArr[i]->SizeOfRawData) / (double)nt->OptionalHeader.SectionAlignment) * nt->OptionalHeader.SectionAlignment; if (rva >= sectionArr[i]->VirtualAddress && rva < (sectionArr[i]->VirtualAddress + SizeInMemory)) { break; } } if (i >= nt->FileHeader.NumberOfSections) { return -1; } else { UINT offest = rva - sectionArr[i]->VirtualAddress; UINT foa = sectionArr[i]->PointerToRawData + offest; //std::cout << "foa:" << foa << std::endl; return foa; } } } void getImportTable32(PIMAGE_DOS_HEADER dos, PIMAGE_NT_HEADERS32 nt, PIMAGE_SECTION_HEADER* sectionArr) { IMAGE_DATA_DIRECTORY importDataDirectory = nt->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_IMPORT]; int num = 0; while (1) { UINT importAddress = VatoFoa32(importDataDirectory.VirtualAddress + nt->OptionalHeader.ImageBase, dos, nt, sectionArr); PIMAGE_IMPORT_DESCRIPTOR importDirectory = (PIMAGE_IMPORT_DESCRIPTOR)((DWORD)dos + importAddress + num * sizeof(IMAGE_IMPORT_DESCRIPTOR)); if (importDirectory->OriginalFirstThunk) { UINT nameoffset = VatoFoa32(importDirectory->Name + nt->OptionalHeader.ImageBase, dos, nt, sectionArr); char* name = (char*)((UINT)dos + nameoffset); num++; UINT offset = VatoFoa32(importDirectory->OriginalFirstThunk + nt->OptionalHeader.ImageBase, dos, nt, sectionArr); if (offset == -1) return; PIMAGE_THUNK_DATA INTTableBegin = (PIMAGE_THUNK_DATA)((UINT)dos + offset); int num2 = 0; while (1) { PIMAGE_THUNK_DATA address = INTTableBegin + num2; if (address->u1.AddressOfData == 0) { break; } else { /*最高位为1时标识导出函数的RVA 最高位为0时标识导出函数的序号*/ if ((UINT)address->u1.AddressOfData >= 0x80000000) { std::cout << "模块名:" << name << "函数序号:" << address->u1.AddressOfData - 0x80000000 << std::endl; } else { UINT functionNameOffset = VatoFoa32(nt->OptionalHeader.ImageBase + address->u1.AddressOfData, dos, nt, sectionArr); PIMAGE_IMPORT_BY_NAME functionName = (PIMAGE_IMPORT_BY_NAME)((UINT)dos + functionNameOffset); std::cout << "模块名:" << name << "导出函数:" << functionName->Name << std::endl; } num2++; } } std::cout << "模块" << name << num2 << std::endl; } else { break; } std::cout << "引用模块数:" << num << std::endl; } } void getExportTable32(PIMAGE_DOS_HEADER dos, PIMAGE_NT_HEADERS32 nt, PIMAGE_SECTION_HEADER* sectionArr) { IMAGE_DATA_DIRECTORY exportDataDirectory = nt->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT]; UINT exportAddress = VatoFoa32(exportDataDirectory.VirtualAddress + nt->OptionalHeader.ImageBase, dos, nt, sectionArr); PIMAGE_EXPORT_DIRECTORY exportDirectory = (PIMAGE_EXPORT_DIRECTORY)((UINT)dos + exportAddress); std::cout << "NumberOfFunctions(导出函数总数):" << exportDirectory->AddressOfFunctions << std::endl; std::cout << "NumberOfName(导出有名称得函数总数):" << exportDirectory->NumberOfNames << std::endl; int i; for (i = 0; i < exportDirectory->NumberOfNames; i++) { //std::cout << "顺序序号:" << i << std::endl; //获取指向导出文件名称得地址 UINT namePointerAddress = VatoFoa32(exportDirectory->AddressOfNames + nt->OptionalHeader.ImageBase + 4 * i, dos, nt, sectionArr); if (namePointerAddress == -1)return; //获取指向名字的指针 UINT* nameAddress = (UINT*)((UINT)dos + namePointerAddress); //获取储存名字的地址 UINT nameOffset = VatoFoa32(*nameAddress + nt->OptionalHeader.ImageBase, dos, nt, sectionArr); if (nameOffset == -1)return; //根据名字指针输出名字 char* name = (char*)((UINT)dos + nameOffset); //找到储存Ordinals的地址 UINT OrdinalsOffset = VatoFoa32(exportDirectory->AddressOfNameOrdinals + nt->OptionalHeader.ImageBase + 2 * i, dos, nt, sectionArr); if (OrdinalsOffset == -1)return; WORD* Ordinals = (WORD*)((UINT)dos + OrdinalsOffset); //找到Ordinals后可以根据Ordinals到AddressOfFunction中找到对应导出函数的地址 UINT* functionAddress = (UINT*)((UINT)dos + VatoFoa32(exportDirectory->AddressOfFunctions + nt->OptionalHeader.ImageBase + 4 * (*Ordinals), dos, nt, sectionArr)); std::cout << "1" << std::endl; std::cout << "顺序序号" << i << "name:" << name << "functionAddress(RVA):" << *functionAddress << std::endl; } } int main() { PIMAGE_DOS_HEADER dos; // const char* FilePath="D:\\IDA\\IDA PRO 7.5 (x86, x64, ARM, ARM64)\\ida.exe";//后续增加输入文件地址直接进行解析D:\\OllyICE_1.10\\OllyDBG.EXE // 创建文件的句柄 HANDLE hfile = CreateFileA("D:\\OllyICE_1.10\\OllyICE.exe", GENERIC_READ, FILE_SHARE_READ, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL); // HANDLE hfile=CreateFileW((LPCWSTR)FilePath,GENERIC_READ,FILE_SHARE_READ,NULL,CREATE_ALWAYS,OPEN_EXISTING,NULL);//创建文件的时候会直接把与文件同名的原本文件直接覆盖掉并且不会以原有的形式进行保存以文件夹形式进行了保存 if (hfile == INVALID_HANDLE_VALUE) { std::cout << "failed to create file" << std::endl; return -1; } DWORD dwFileSize = GetFileSize(hfile, NULL); // 创建文件的映射 HANDLE hfilemapping = CreateFileMapping(hfile, NULL, PAGE_READONLY, 0, dwFileSize, NULL); if (hfilemapping == NULL) { std::cout << "failed to create filemapping" << std::endl; return -1; } // 创建文件的视图 LPVOID fileView = MapViewOfFile(hfilemapping, FILE_MAP_READ, 0, 0, dwFileSize); // 返回视图的起始地址 if (fileView == NULL) { std::cout << "failed to create fileview" << std::endl; return -1; } // 检索DOS头 dos = reinterpret_cast<PIMAGE_DOS_HEADER>(fileView); std::cout << "e_magic:" << dos->e_magic << std::endl; std::cout << "e_lfanew:" << dos->e_lfanew << std::endl; // 定义NT头 移动dos头指针到pe头 PIMAGE_NT_HEADERS32 nt; nt = (PIMAGE_NT_HEADERS32)((DWORD)dos + dos->e_lfanew); std::cout << "Machine:" << nt->FileHeader.Machine << std::endl; std::cout << "AddressOfEntryPoint:" << nt->OptionalHeader.AddressOfEntryPoint << std::endl; std::cout << "ImageBase:" << nt->OptionalHeader.ImageBase << std::endl; std::cout << "SizeofHeaders:" << nt->OptionalHeader.SizeOfHeaders << std::endl; std::cout << "Numberofsection:" << nt->FileHeader.NumberOfSections << std::endl; //遍历节头 IMAGE_SECTION_HEADER** sectionArr = (IMAGE_SECTION_HEADER**)malloc(sizeof(IMAGE_SECTION_HEADER*) * nt->FileHeader.NumberOfSections); PIMAGE_SECTION_HEADER sectionHeader; sectionHeader = (PIMAGE_SECTION_HEADER)((UINT)nt + sizeof(IMAGE_NT_HEADERS32)); int num = 0; while (num < nt->FileHeader.NumberOfSections) { PIMAGE_SECTION_HEADER section; section = (PIMAGE_SECTION_HEADER)((UINT)sectionHeader + sizeof(IMAGE_SECTION_HEADER) * num); sectionArr[num++] = section; std::cout << "Name:" << section->Name << std::endl; } getExportTable32(dos, nt, sectionArr); getImportTable32(dos, nt, sectionArr); // 关闭映射和打开的句柄 UnmapViewOfFile(fileView); CloseHandle(hfilemapping); CloseHandle(hfile); return 0; }
对节进行操作 扩大节 扩大节目的 在PE文件的空白节不足以使用我们想进行的操作的时候,我们需要对节这个有指向权限的段进行扩大,以达到我们可以写入更大的恶意代码去执行。
思路 扩大节,最好直接扩大最后一个节进行。如果想扩大任意一个节就需要对DataDirectry中其他的节的偏移地址进行修改,同时对其他的节加上相对应的偏移,但是直接扩大最后一个节就不会有这样的问题(节是顺序存储的)。
合并节 新增节 新建节表进行shellcode注入